爬过豆瓣的同学应该都有过这样的经历,一开始爬取的过程挺正常的,但爬着爬着就不能获取到数据了。这是因为豆瓣对IP作了限制,如果短时间内来自同一个IP的请求太多,就会禁止来自这个IP的访问,我们的爬虫也就无法继续获取到数据了。
豆瓣的反爬
我们先来真实地感受一下豆瓣的反爬。假如我们有这样一个豆瓣的爬虫,这个爬虫是要爬取豆瓣上某几个标签页下的图书的数据(像下面这样的页面里的数据)

爬虫的代码如下(这里只是为了展示豆瓣的反爬机制,代码作了简化)
def get_books_by_page(tag, page_no):
start = page_no * 20
url = "https://book.douban.com/tag/{}?start={}&type=T".format(tag, start)
headers = {"User-Agent": "User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)"}
try:
#r = requests.get(url, headers=headers, verify=False, proxies={"https": proxy})
r = requests.get(url, headers=headers, verify=False)
content = r.content.decode("utf-8")
root = etree.HTML(content)
items = root.xpath('.//li[@class="subject-item"]')
print(r.status_code, len(items))
books = []
for item in items:
title_node = item.xpath('.//div[@class="info"]/h2/a')[0]
name = title_node.attrib["title"]
url = title_node.attrib["href"]
books.append({"name": name, "url": url})
return books
except Exception as e:
msg = str(e)
return []
if __name__ == "__main__":
tags = ["SQL", "数据分析", "计算机"]
for tag in tags:
page_no = 0
while True:
books = get_books_by_page(tag, page_no)
if len(books) < 20:
break
page_no += 1
上面的爬虫会爬取SQL、数据分析和计算机这三个标签下的所有图书。每爬取一页数据,我们都会打印出HTTP返回码 r.status_code 和爬取到的图书的数量 len(items) 。
我们在命令行窗口运行这个爬虫,可以看到这样的结果
200 20
200 20
200 20
200 20
200 20
200 20
200 20
200 20
200 20
...
上面的输出表明爬取的页面都返回了HTTP 200,并且获取到了每一页里面的20条图书信息。
但如果我们多运行几次程序后,结果就变成了下面这样了
200 0
200 0
200 0
HTTP还是返回200的响应,但我们获取不到页面里的图书信息了,因为我们的爬虫被禁了。
要解决爬虫被禁的问题,一个直观的思路就是使用代理池,每次爬取页面我们都使用不同的IP发出请求,这样就可以避免同一个IP频繁发出请求被禁的情况。
代理按照是否匿名,大致可分成这样几类
- 透明代理
- 匿名代理
- 高匿代理
透明代理在HTTP头里设置了你的真实IP,服务器可以通过HTTP头知晓你真实的IP。
匿名代理虽然隐藏了你的真实IP,但服务器还是知道你使用了代理。
高匿代理不仅隐藏了你的真实IP,而且让服务器无法发现你在使用代理,这是我们自建代理池的最佳的选择,我们下一步自建代理池的步骤中用到的也是高匿代理。
自建代理池
西刺代理([]https://www.xicidaili.com/))是一个提供免费代理的网站,他的首页是下面这样的
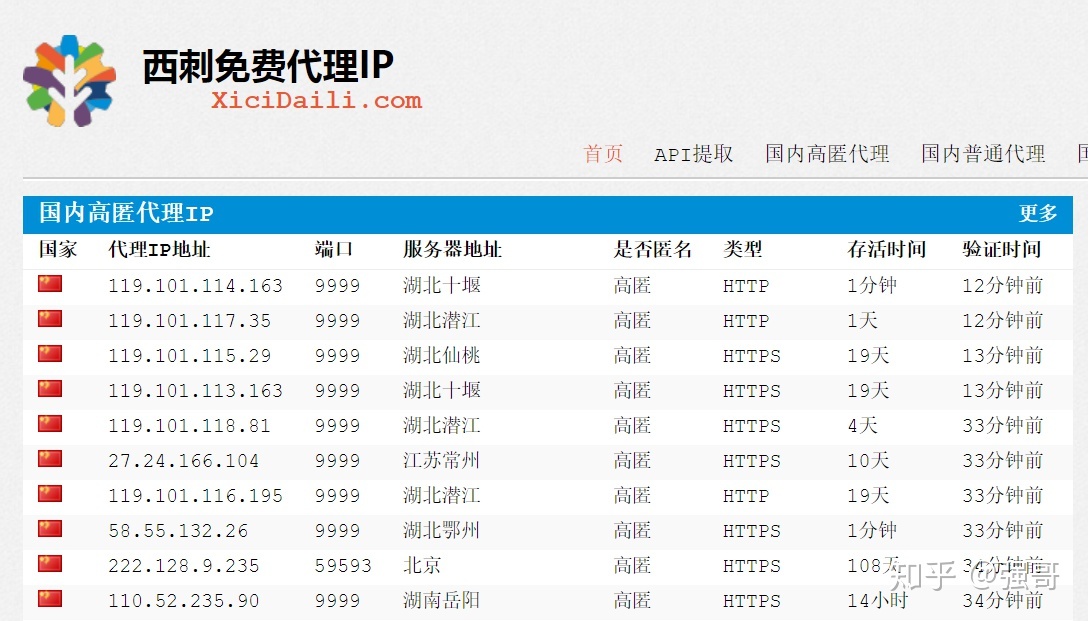
我们通过爬取西刺上可用的免费高匿代理,来建立我们的代理池。
爬取西刺高匿代理的代码如下
import re
import requests
from lxml import etree
def get_xici_proxy(page_no):
url = "https://www.xicidaili.com/nn/{}".format(page_no)
headers = {"User-Agent": "User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)"}
r = requests.get(url, verify=False, headers=headers)
content = r.content.decode("utf-8")
root = etree.HTML(content)
tr_nodes = root.xpath('.//table[@id="ip_list"]/tr')[1:]
result = []
for tr_node in tr_nodes:
td_nodes = tr_node.xpath('./td')
ip = td_nodes[1].text
port = td_nodes[2].text
proxy_type = td_nodes[4].text
proto = td_nodes[5].text
proxy = "{}://{}:{}".format(proto.lower(), ip, port)
uptime = td_nodes[8].text
if proxy_type == "高匿" and proto.lower() == "https":
result.append(proxy)
return result
上面的get_xici_proxy函数每次获取一个页面的代理。因为豆瓣图书的URL都是HTTPS的,所以我们这里只关心HTTPS的代理,上面的代码中我们筛选出高匿的并且是HTTPS的代理。
爬下了免费代理以后,接下来,我们来验证一下这些代理是不是可用。我们通过代理去访问豆瓣的网页,测试代理的有效性。代码如下
def test_proxy(proxy):
https_url = "https://book.douban.com/tag/SQL?start=20&type=T"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
try:
proxies = {"https": proxy}
r = requests.get(https_url, headers=headers, verify=False, proxies=proxies, timeout=10)
content = r.content.decode("utf-8")
root = etree.HTML(content)
items = root.xpath('.//li[@class="subject-item"]')
print(r.status_code)
if r.status_code == 200 and len(items) == 20:
return True
return False
except Exception as e:
msg = str(e)
return False
我们获取到这样几个有效的代理
# proxy文件内容
https://110.52.235.11:9999
https://119.101.114.44:9999
https://119.101.117.59:9999
https://112.85.129.162:9999
https://119.101.112.66:9999
https://119.101.117.72:9999
https://125.123.136.156:9999
https://119.101.112.210:9999
https://119.101.114.72:9999
https://119.101.112.202:9999
https://119.101.112.173:9999
https://119.101.112.251:9999
https://119.101.112.64:9999
https://119.101.114.103:9999
https://119.101.112.172:9999
https://119.177.210.163:9999
我们把上面测试有效的代理存入到一个叫proxy的文件中。
接下来,我们实现一个Proxy类来获取这个列表中的代理
class Proxy(object):
_instance = None
def __new__(cls, proxyfile):
if not isinstance(cls._instance, cls):
cls._instance = super(Proxy, cls).__new__(cls)
with open(proxyfile) as f:
content = f.read()
lines = content.split("\n")
cls._instance._proxies = lines[:-1]
cls._instance._curr = 0
return cls._instance
def get_proxy(self):
idx = self._curr % len(self._proxies)
proxy = self._proxies[idx]
self._curr += 1
return proxy
上面的Proxy是一个Singleton的类。get_proxy方法用于从代理列表中获取代理,每次使用一个代理,如果所有的代理都用过了,我们回到第一个代理,重新开始选择。
好,到这里我们就建立我们自己的代理池,并且创建了一个获取代理的类Proxy。
接下来我们修改我们之前豆瓣爬虫的代码,我们使用代理池中的代理来发出请求。我们将get_books_by_page函数修改成如下
def get_books_by_page(tag, page_no):
start = page_no * 20
url = "https://book.douban.com/tag/{}?start={}&type=T".format(tag, start)
headers = {"User-Agent": "User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)"}
inst = Proxy("proxy")
proxy = inst.get_proxy()
try:
r = requests.get(url, headers=headers, verify=False, proxies={"https": proxy}, timeout=10)
content = r.content.decode("utf-8")
root = etree.HTML(content)
items = root.xpath('.//li[@class="subject-item"]')
print(r.status_code, len(items))
books = []
for item in items:
title_node = item.xpath('.//div[@class="info"]/h2/a')[0]
name = title_node.attrib["title"]
url = title_node.attrib["href"]
books.append({"name": name, "url": url})
return books
except Exception as e:
msg = str(e)
return []
我们再次运行我们的豆瓣爬虫,可以看到如下的输出
200 20
200 20
200 20
200 20
...
现在爬虫又重新开始工作,可以获取到图书的信息了。
通过这样的自建代理池,我们破解了豆瓣的反爬。不过需要注意的是,很多免费代理有效时间比较短,毕竟是免费的,稳定性没保障。大家获取免费代理后,还是要趁热尽快使用。如果要追求稳定性,建议大家还是使用付费代理。